
Clearway Phoenix started after a simpler V1 matching calculator failed. The original system could only do literal keyword filtering, which meant a student looking for economy would miss programs labeled business or finance. That failure exposed the real problem: the agency was trying to make high-stakes placement decisions from messy spreadsheets, shallow logic, and manual cross-referencing.
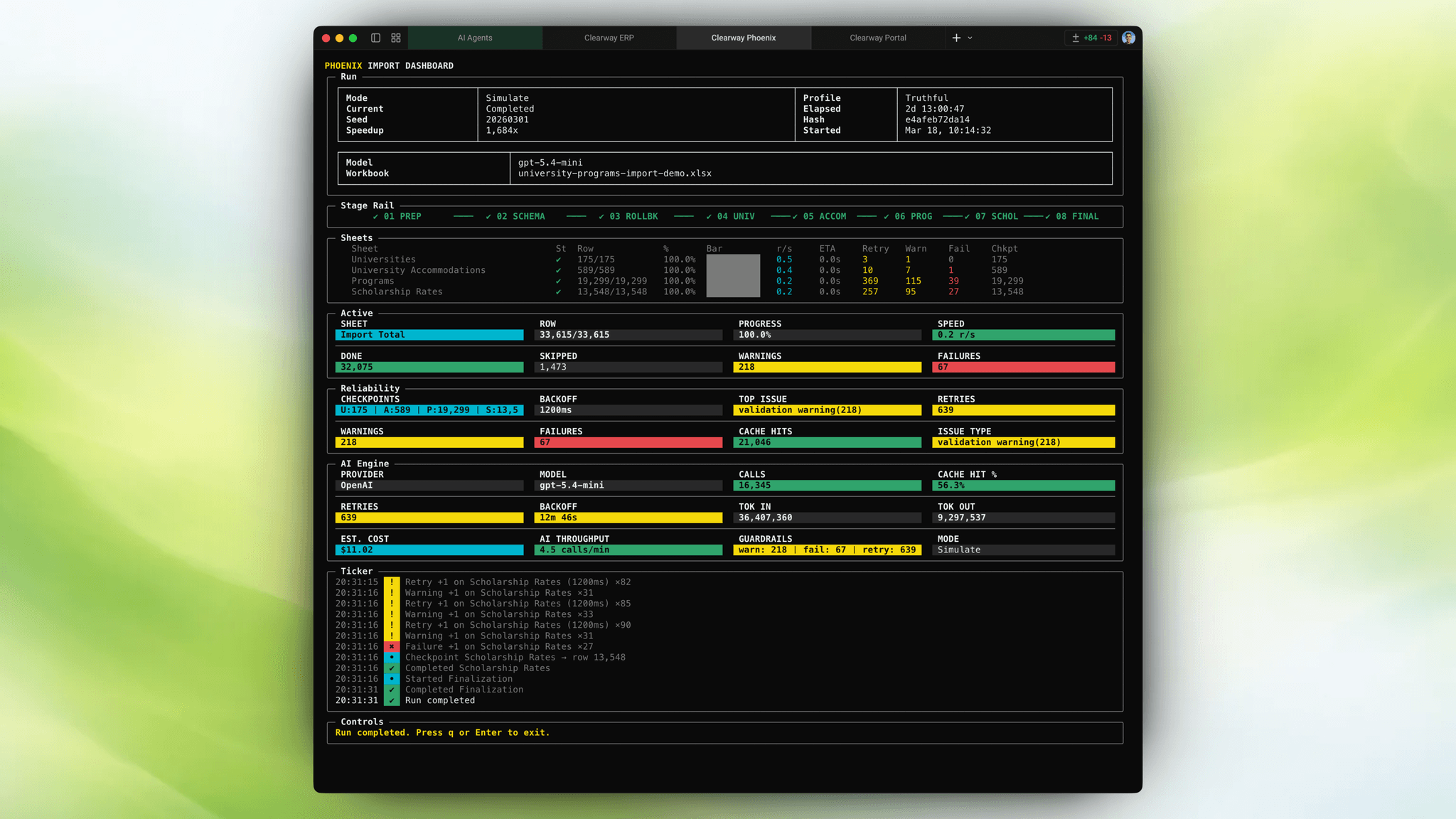
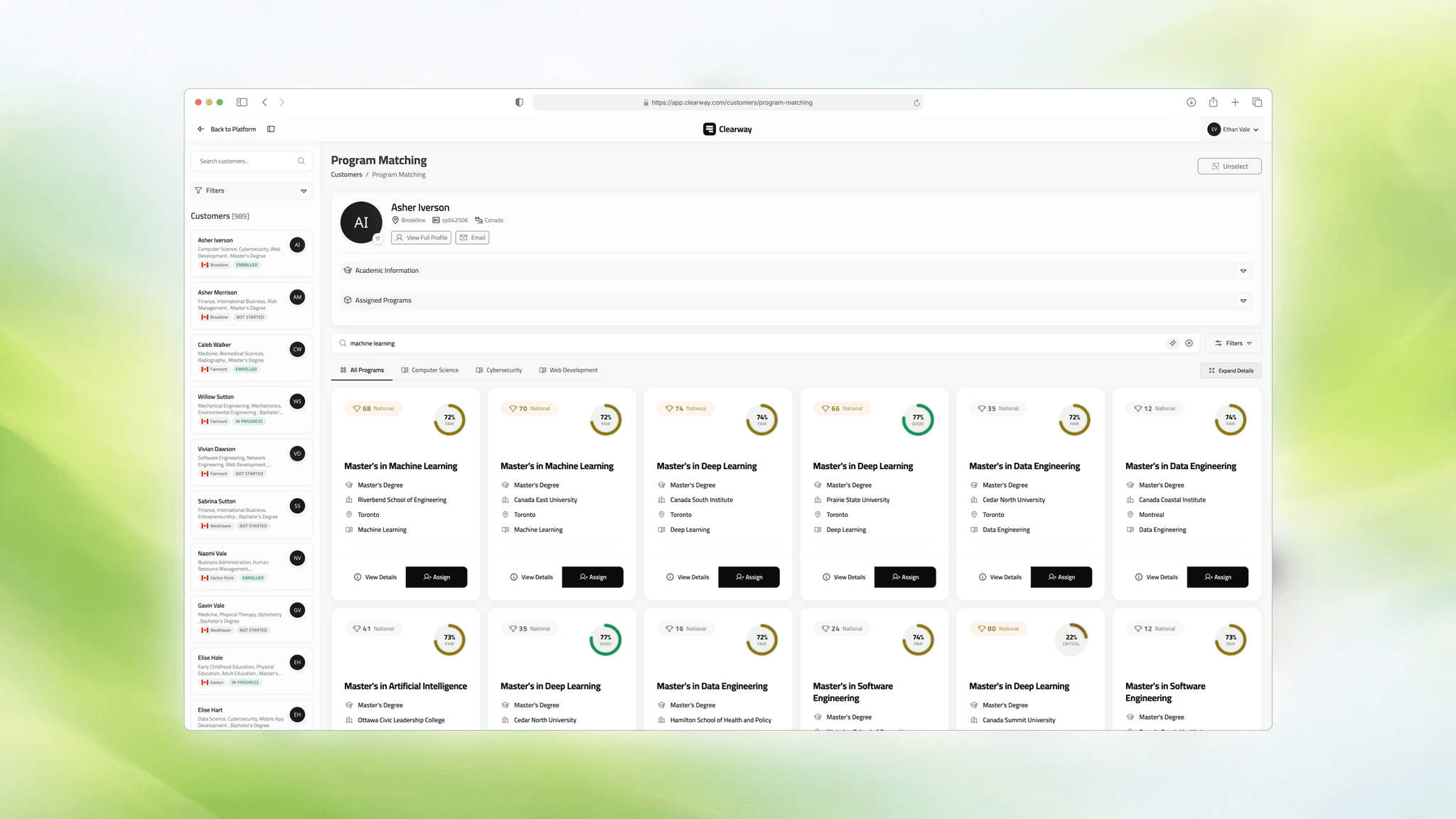
I rebuilt the workflow as a sequence of connected systems: a normalized data model, a resumable AI-powered import pipeline, and a real-time matching engine that could be used during live advisor calls.
Rebuilding the data model
The first decision was sequencing. I did not start by importing data. I started by building the place that data needed to live.
The legacy system was too flat to support intelligent matching. Critical business rules lived inside notes fields: nationality restrictions, scholarship variants, language thresholds, fee structures, and accommodation details. That makes data display possible, but it makes reasoning impossible.
So the first pass rebuilt the foundation as a normalized schema across universities, programs, scholarships, locations, and reference data. The goal was not elegance for its own sake. The goal was queryability. If a future recommendation engine needed to reason about grade requirements, scholarship coverage, or field alignment, those things had to exist as real structured relationships first.
| Decision |
|---|